从词向量到XLNet模型,预训练技术的演进不断地推动着自然语言处理(NLP)领域的发展,本文从朴素的神经网络语言模型(NNLM)开始,逐步探讨Word2Vec、BERT等模型原理及其作预训练在NLP中的应用…
1. 神经网络语言模型
NNLM
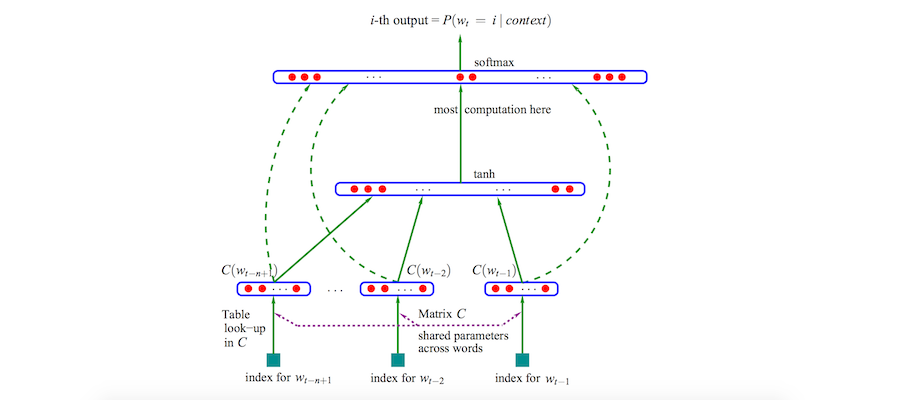
封面图所示的神经网络模型,始见于Bengio团队2003年一篇名为“A neural probabilistic language model”的论文。
作为将神经网络用于语言模型(Language Model,简称LM)问题的开山之作,论文用一个单隐层NN来对“下一词预测”问题进行建模。设待预测词为Wt,输入为前n个词W<t = [Wt-n+1, ..., Wt-2, Wt-1],one-hot编码形式的输入序组W<t经过变换后得到每个词的向量表示C<t = [C(Wt-n+1), ..., C(Wt-2), C(Wt-1)],对C<t序组进行cancat后依次经过隐层激活与softmax输出,得出Wt是词典序第i个词的概率:
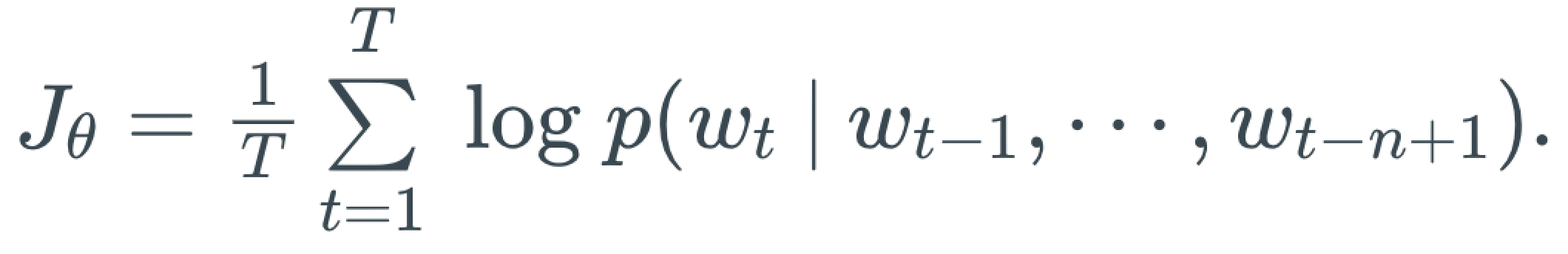
训练时可采用最大化似然来衡量损失,由损失函数可得梯度进行BP运算,实现神经网络的参数更新。以语料中的某条训练样本W=[W1, W2, ..., Wt,..., WT],其训练的损失为:
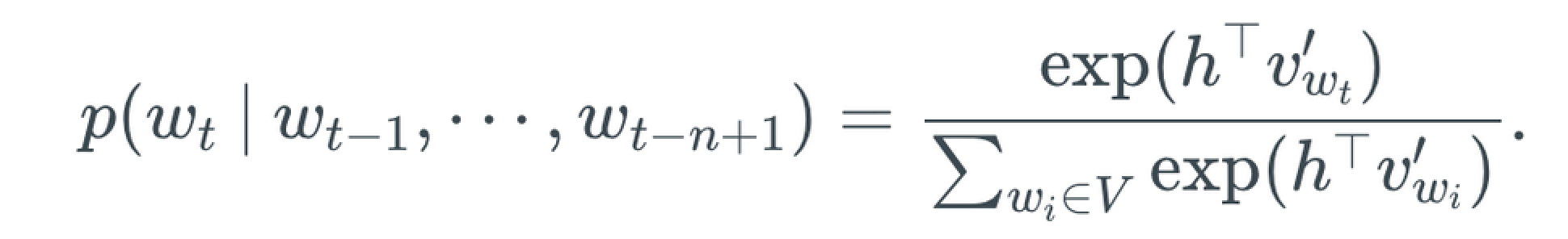
Word Embedding
这儿,我们需要重点关注网络训练得出的两大参数矩阵:C和V。C是将one-hot编码形式的输入词变换为定长形式的向量表示,V是将隐层输出H映射到softmax层上每一维输入的连接权值矩阵。以C为例,其矩阵的每一行对应了一个词在高维空间中的向量化表达,即word embedding,为了简便,我们直接称之为”词向量”。V的数值含义可与C类比,进一步地,我们将C给出的词向量称为输入词向量,V给出的词向量称为输出词向量。
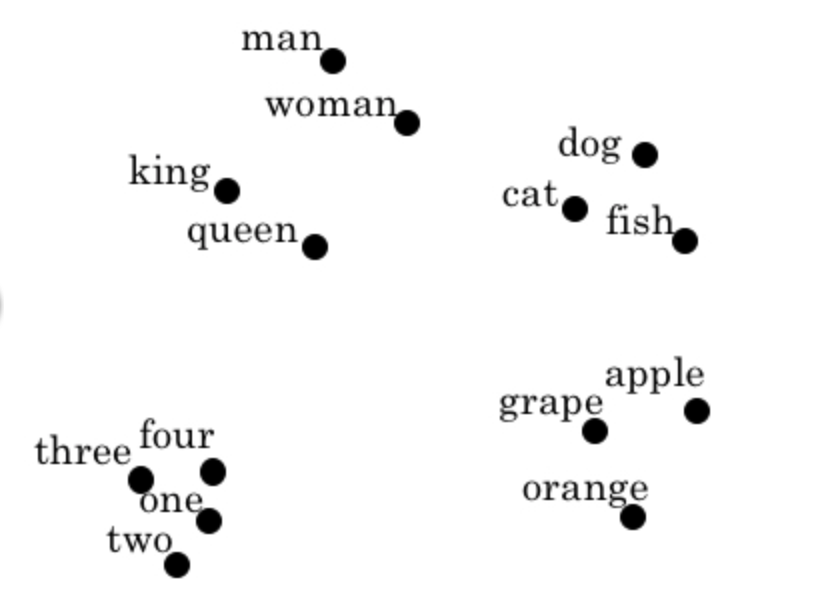
说起词向量,想起一个老生常谈的例子:C(king) - C(queen) ≈ C(man) - C(woman),即当我们把词从one-hot编码映射为向量编码时,向量本身的数值大小、方向,向量之间的运算,隐式地体现了词的语义信息。理解并使用好词向量(如同体会embedding这个名词真切含义那样),对于我们理解自然语言处理的内在机理,提升工程应用水平有很大的帮助。
Lookup Table
这儿,我们考察输入词向量。如前所述,输入词向量是神经网络语言模型(NNLM)训练后得到的副产物,其数值存储于one-hot输入层到embedding输入层之间的连接权值矩阵C中,假设输入one-hot编码维度为1*m,embedding维度为1*n,则C的大小为m*n。
不妨想想这样一种思路:one-hot编码对于我们而言,只不过是某个词的一种指代方式,实际上我们直接用词向量来指代某个词又何尝不可呢?假设有这样一个映射表,key是词的索引,value是词的词向量,那么获取某个词的词向量只需查询该表即可。在神经网络前向计算(Feed Forward)时,直接从输入词查表后得到的词向量出发进行前向计算;而在反向传播(Back Propagation)时,参数也直接更新到词向量为止。自此,我们忽略掉了所谓的one-hot、C矩阵等概念体,以词向量(word embedding)作为一个词的基本指代特征。
这儿所说的索引到词向量的映射表,业界称之为lookup table。随着词向量被广泛用作基础特征,lookup表也随之成为一个重要的训练目的,预训练好的lookup表往往可直接迁移应用于其他诸如NLP、推荐的任务中。
2. Word2Vec
CBOW & Skip-Gram
前文说到,词向量的生成(lookup表的建立)是一项重要的预训练任务,但若只是依托于NNLM的训练来收集副产物的方式,对于词向量获取这个任务本身而言貌似并不高效。有没有什么模型或方法是以高效地生产词向量为直接目的呢?当然有,其中的典型即是Mikolov等人在2013年前后提出了CBOW和Skip-Gram。
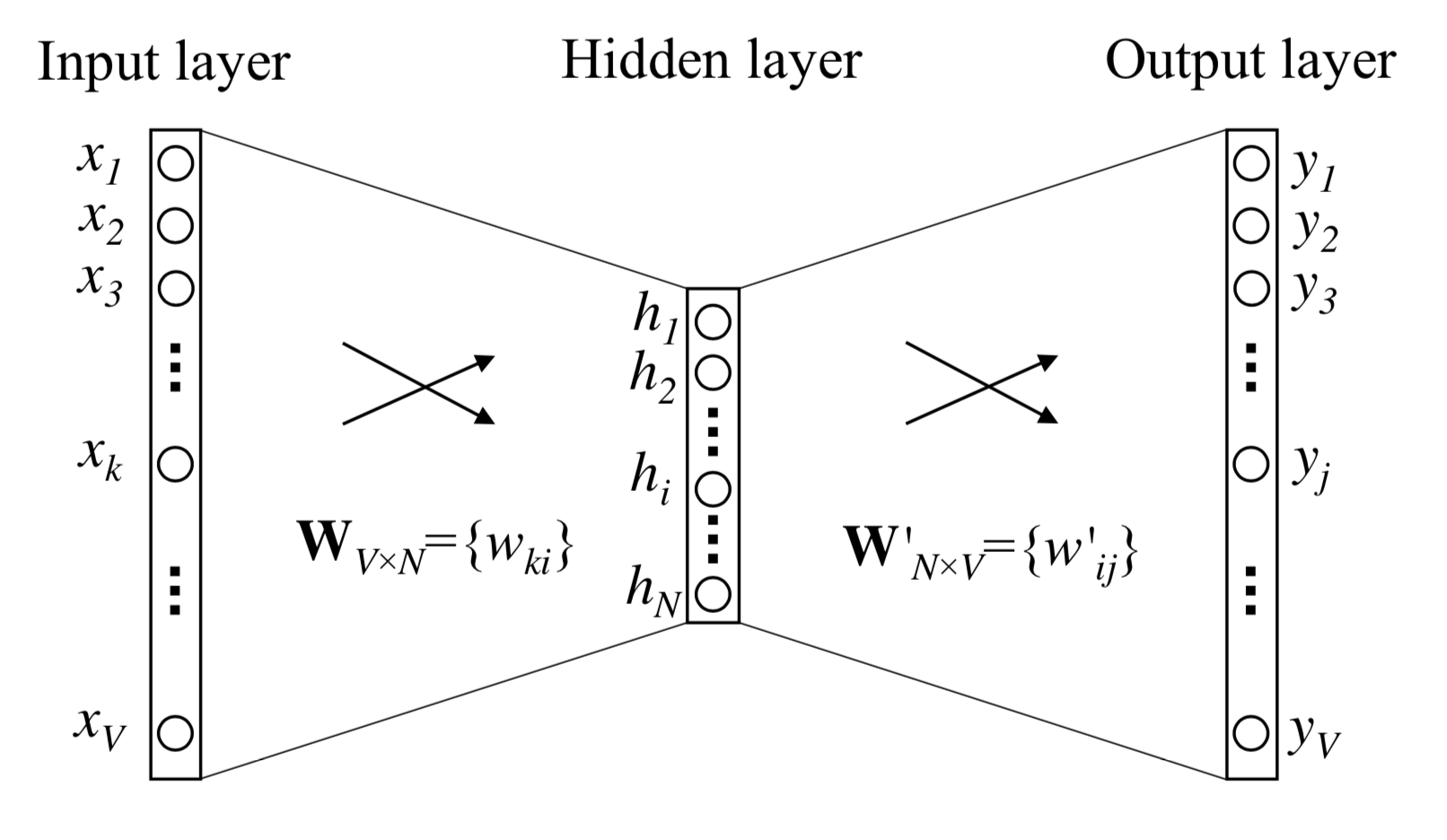
如上图所示的一个极简NNLM,W和W'分别对应输入词向量矩阵和输出词向量矩阵。设该LM任务为from word i pred word j,无隐层激活时,输出概率为:
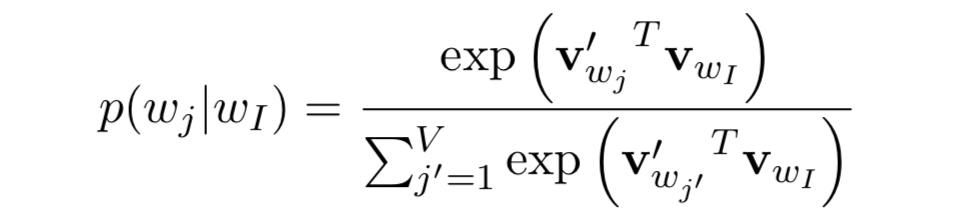
式中v和v'即上述输入输出两个矩阵所包含的词向量,也是word2vec的学习目标。在BP梯度更新的过程中,有关联的输入vi和输出vj向量空间上会靠近,无关的会排斥,(关联的简明含义如:wi、wj出现在同一句话中,某条样本P(wj|wi)=>1…)。训练过程反复迭代,词向量因而产生了隐含语义。
对上图所示简化的NNLM进行拓展,如模型变成由上下文多个词预测某目标词时,该多输入单输出模型即是CBOW(Continuous Bag-of-Word Model);又如果将模型任务改成由某个目标词预测其上下文多个词时,这种单输入多输出的模型即是Skip-Gram;
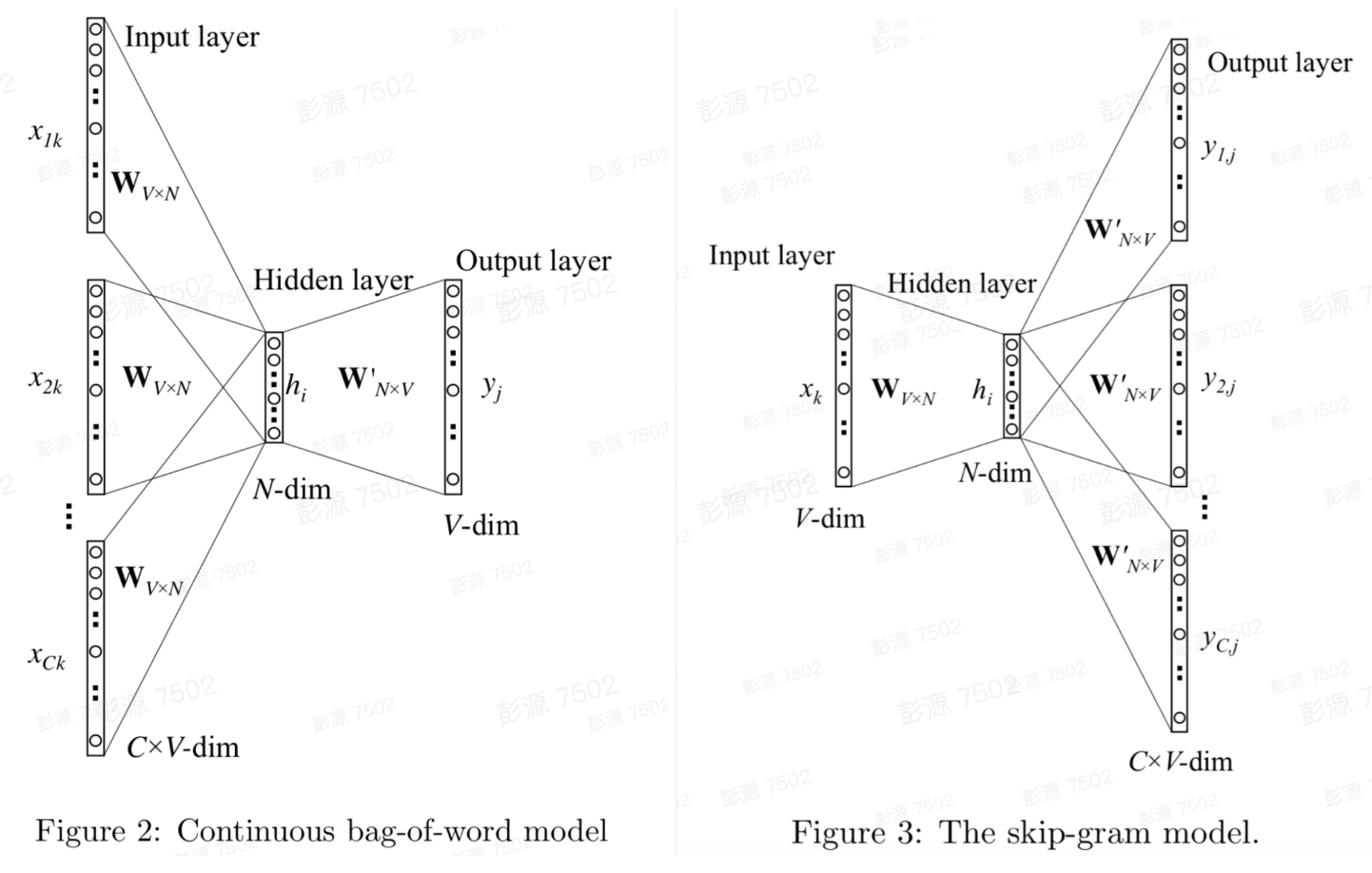
从CBOW、Skip-Gram的模型结构可知,输入词one-hot编码维度为词典大小V,某词Xk经过输入矩阵变换后得到隐层向量Hk,Hk=W(k:)=vk,即隐层向量为输入词的词向量。经过input->hidden,Xk从one-hot->word vector,原本高维表示的词特征(one-hot),被一个低维特征表达(word vector),该过程实现的是输入空间的压缩,且被压缩后词特征具备一定的语义信息,这就是word2vec的内涵所在。
不管是前节提到的经典NNLM模型,还是这儿的CBOW和Skip-Gram,其输出都是softmax概率向量,向量的维度等同于词典大小V。V往往是很大的,这使得我们对每条样本在输出层直接作softmax(的分母累加和项)时将面临很大的计算开销。这往往是一项任务所不能承受的。实际上,输出维度较大的softmax模型都面临类似问题,相关的优化方法挺多,诸如:层次化softmax、负采样等等。
Input vs Output
具有一定词向量工具使用经验的同学会发现,我们在工程上用作输入特征级word embedding的词向量,多是上文所说到的输入词向量v,与此同时我们还知道有输出词向量v',这两种embedding的区别是?输入词向量为何被更多的采用呢?可能的原因有:(内容有个人揣测的成分)
- 起初NNLM为解决输出层Softmax的计算优化问题,采用了诸如分层softmax等trick,便无法产生输出词向量,于是只能获取输入词向量来使用。
v与v'看似对称,实际上分属于不同的空间,输入空间更多的是获取词本身的语义信息(word),输出空间更多的是学习词与词间的上下文关联性(context),emm…怎么理解这个想法呢,举个不成熟的例子,大家或许听说过推荐中所谓的啤酒-尿布案例,假设现在有三个词:白酒、啤酒、尿布,对于输入层而言,更倾向于去捕获白酒-啤酒作为酒的词义本身特征,而输出层更倾向于捕获啤酒-尿布作为上下文的关联特征。不同于词义本身特征,上下文关联特征往往会与具体的业务场景相关联,所以大家在迁移应用的时候,选用输入词向量似乎更合适了。- 结合2.进一步考虑,假设现在有从英文书籍语料预训练好的词向量,如下游任务搜索推荐,可能我们更多倾向于采用输入词向量,但倘若下游任务是英译中的机器翻译,或可采用输出词向量。事实上,已有许多相关研究和应用是以输出词向量为出发的。
3. ELMo和GPT
模型级预训练
随着word2vec的推广,基于各种语料库预训练好的词向量广泛地应用于各种下游任务。但是,随着技术需求的提高,人们逐渐感到单靠词向量这种级别的pretrain embedding feature是不够的,模型级别的预训练由此衍生,其中的先驱便是ELMo、GPT。
这儿我们先举个关于词歧义的例子来直观感受下词向量的局限性。设两个句子:(a)this apple is delicious.(b)apple is a great company. 可以看到,两句中都出现了apple这个词,从词向量的角度出发两个句子的apple词输入并无不同,但是结合上下文语义我们却可以明显地感觉到这两个apple的歧义(毕竟前面是吃的苹果,后面时苹果公司^-^)。对于词歧义这个广泛存在的问题,词级别的特征很难表示得当,这时候就需要语法、语义层次的特征来做更强的表征了。
如所熟知的那样,在CV领域大放异彩等多层卷积神经网络,正是在完一个图像局部特征捕获->全图信息认知的过程;而NLP任务普遍的多层循环神经网络,也常在完成一个词汇局部特征捕获->语段信息认知的过程,网络中更高层的RNN单元,更多的结合了上下文的语法语义信息。那么从预训练的角度出发,如何即生产某词的词向量embedding,也能生产词在更高层次的语义语法embedding呢?考虑到语法语义级别的embedding是要结合具体上下文的,无法直接预先给出(类似lookup表那样),但我们已经知道这种embedding的提取方法就存在于模型之中,为何不能直接预训练模型呢?当然可以。之前模型级预训练的一大障碍可能是数据集的缺位,但当时间来到201x年,海量语料库的出现(如SQuAD),进行model-level pretrain变得切实可行起来。
ELMo
ELMo全称embedding from language models,出自名为Deep contextualized word representations的论文,正如论文标题字面意思那样,ELMo是结合了上下文的(contextualized)基于模型(model-based)的word embedding预训练方法。模型采用双向多层lstm,不同层的隐向量代表了不同层次的词表征(word representation),其应用示意如下:
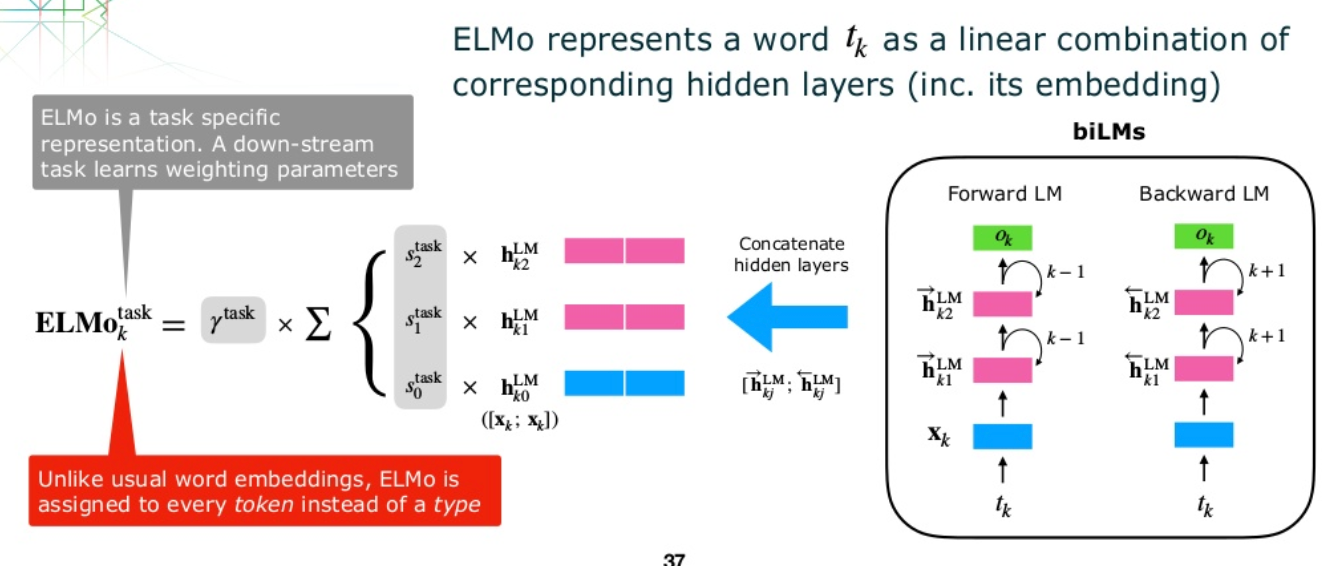
当预训练好的ELMo模型整体迁移用于下游任务的时,对于下游任务输入序列中的某个词xk=hk0,可得其ELMo各层隐向量hk1、hk2...,越往上层的隐向量整合的上下文语义信息更多。然后将各层向量输出到下游任务用于输入,当然输入形式可自定(加权pooling、concat均可)。
GPT和Transformer
GPT全称generative pre-training,同样作为模型级预训练,模型沿用了单向结构,并创新地引入Transformer替代以往的RNN单元来作为LM的基本特征提取器。
下图从左向右依次给出了self-attention单元、multi-head attention单元和transformer encoder单元三种结构。可以看到,transformer采用了multi-head attention作用于输入,所谓multi-head,即是将输入拆分出多组(Q、K、V),灌入多个self-attention单元,最后concat起来。实验表明transformer采用这个multi-head的attention机制,相较于单层attention具有更好的效果(实际上,产生更好效果的内部机理在业界还存疑)。
![]()
4. BERT
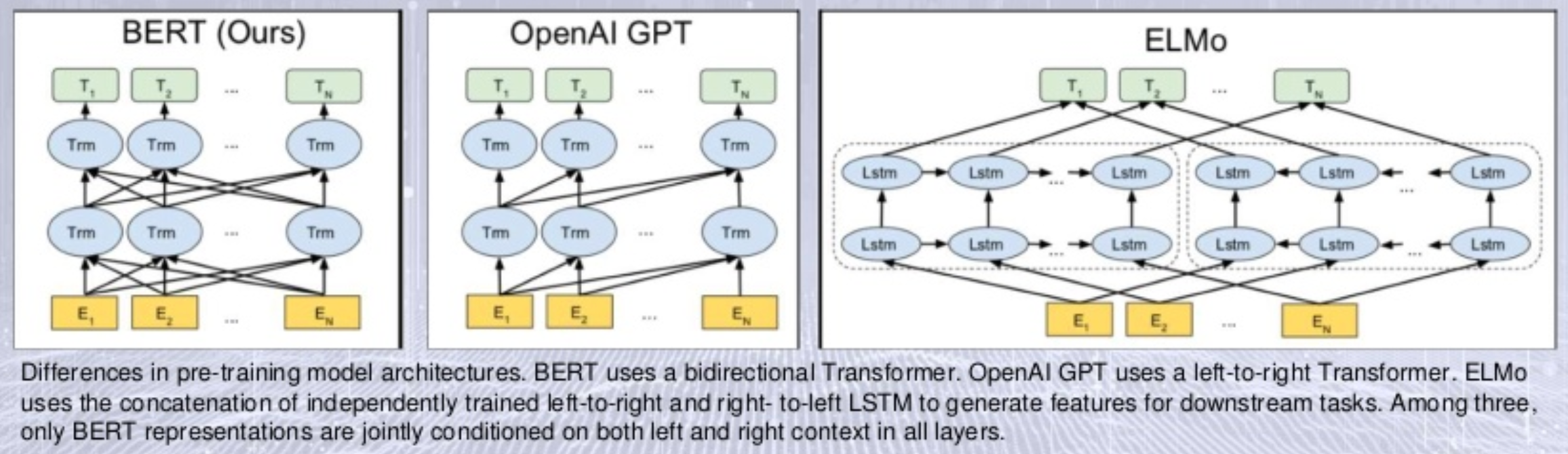
上图直接给出了BERT、GPT、ELMo三种模型结构对比,可以看出,BERT很像是整合了GPT和ELMo的集成改进版。
BERT,全称Bidirectional Encoder Representations from Transformers,从其字面含义中可提取出两个关键点:Bidirectional和Transformer,这两个点道出了BERT的核心,即实现上下文融合输入的Mask机制,以及Transformer。
Mask机制
Masked Language Model(MLM),BERT预训练阶段对输入进行了Mask改造,用一个例子来说明输入Mask机制干了啥事:假设有完形填空任务:冬天来了__还会远吗。
- 原有的单向语言模型(如GPT)的预测机制是:
冬天来了 -> 春天; - 原有的双向语言模型(如EMLo)的预测机制是:
冬天来了 -> 春天+还会远吗 -> 春天; - 采用Mask机制的双向语言模型(如BERT)的预测机制是:
冬天来了__还会远吗 -> 春天;
如上稍加对照,便可看出采用Mask机制的BERT与之前的不同所在。传统的单向语言模型,具有无法使用下文的“缺陷”,这尤其对一些偏自然语言理解(NLU)类的任务不友好。而原有的双向语言模型,虽说用了下文,如ELMo,实际上却是正反向分离的,如上图右所示的那样,其隐层参数不共享,致使其只是机械地将基于上文的预测和基于下文的预测合起来。
Mask机制作用后的输入,在很大程度上还原了如例子中所给出的完形填空式的预测场景,这种机制对机器翻译、阅读理解等众多的语言模型应用场景有着明显的理论亲和度,
Mask机制作用于训练阶段,可简单描述为,对于某条输入样本序列,先mask掉部分输入(如替换为[MASK]),然后(基于其他context)来预测被mask掉的输入。具体在实现时,还有一些小的trick,如为防止mask的词被模型记忆式学到[MASK]符上,将80%被mask的词记为[MASK]符,剩余20%中一半维持原词,一半取随机词代替…。
预测下一句
Next Sentence Prediction(NSP),BERT的预训练任务之一是预测下一个句子,以期模型能捕获句子间的关系。其做法是,从语料库中抽取句子对<A,B>,其中B以概率P为A的下一句,概率1-P为随机的句子。
输入输出
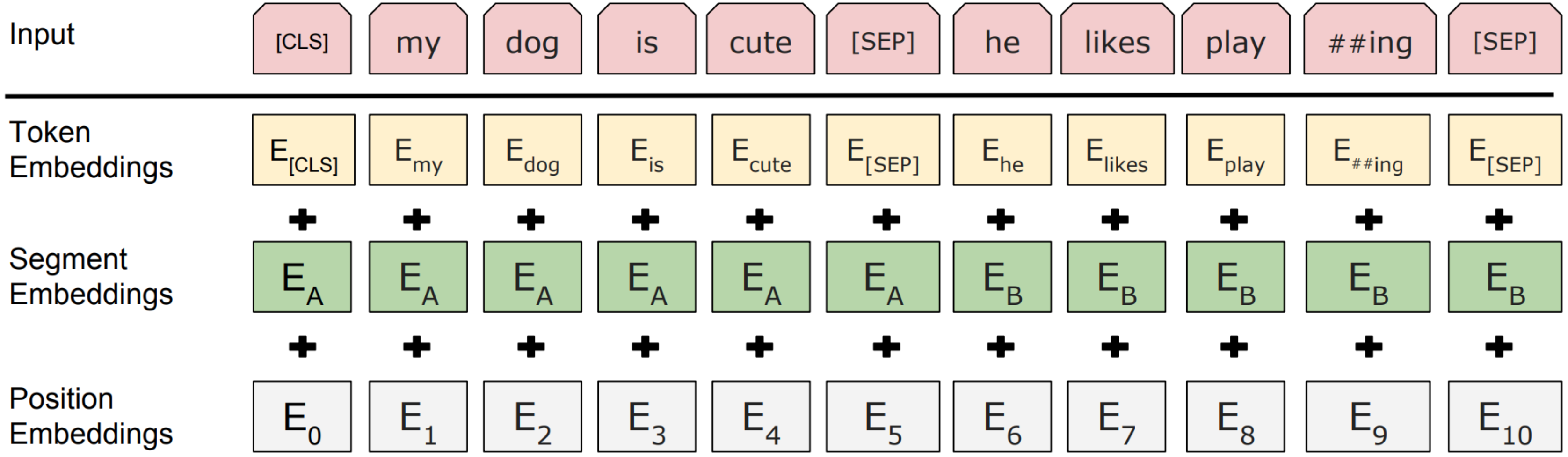
如上图所示,BERT的每个输入词有三个不同含义的embedding:Token Embedding、Segment Embedding、Position Embedding,分别对应词本身、句段、词在句段中的位置,三种embedding求和得到词的混合embedding输入到transformer中。
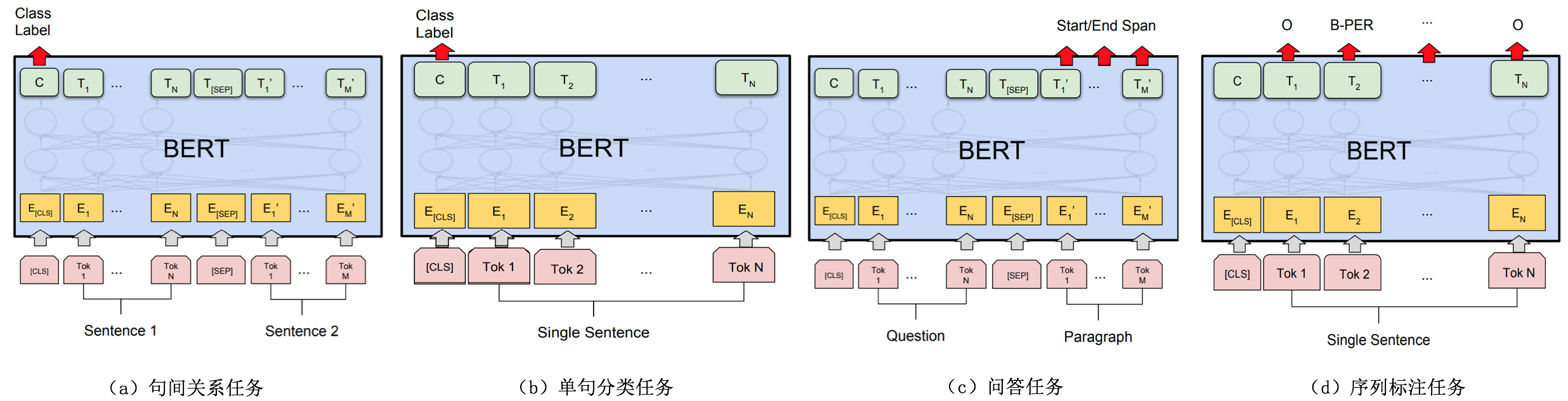
下图给出了BERT用于一些语言处理任务的示意。对于句子层面的任务如句子间的关系、句子分类等,可采用[CLS]位置输出作为下游输入,结合前面NSP子任务,我们认为[CLS]位置的输出隐含了句子类别及上下句关系。对于序列标注等词级别的任务,可采用各个词位置上的输出作为下游输入,这时各个token输出带有丰富的词本身的信息和上下文信息。
5. XLNet
自BERT大放溢彩起,NLP任务全面进入model-pretrain->task-finetune两阶段模式。然而,单就BERT模型本身而言,它也面临着一些问题:
pretrain-finetune discrepancy,BERT的一大创新是通过MASK机制在训练时成功地将上下文融合,但在某些任务的预测时无法先获取下文,这就导致了训练和预测两阶段的不一致,这也是MASK机制对于一些自然语言生成(NLG)类任务不太友好的主要因素。条件独立假设存疑,BERT将某词MASK后由其他词预测该词的机制,建立在条件独立的假设之上,然后当一条样本中被MASK词本身存在关联时,这个假设失效,由此可能导致效果受损。举例,如
我爱北京,北和京两个强关联的词同时被MASK,预测任务P(北京|我爱)=P(北|我爱)*P(京|我爱)便难以成立,即BERT忽略了被MASK词之间的关联。
XLNet,针对性的解决了BERT面临的问题,使模型结构看上去仍然是单向的预测形式(依据前面的词预测后面的词),训练时却融合了上下文信息(间接用上了后面的词)。如此克服pretain-finetune不一致的问题,提升了预训练模型对更多NLP任务的迁移适用性。
Permutation
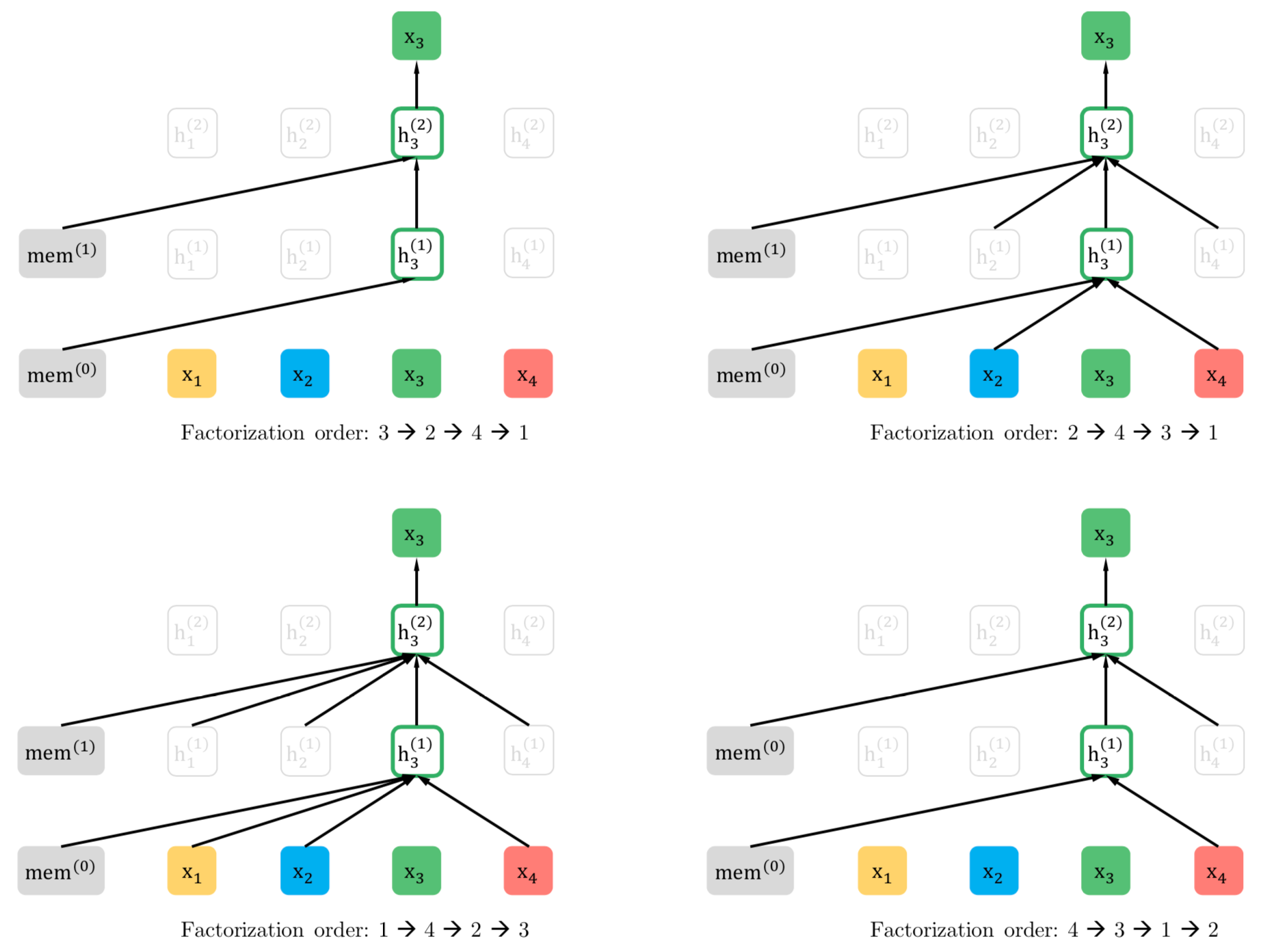
XLNet在训练时是如何用上了后面的词,又保持了从前往后预测的队形的呢?这里,它提出了对输入进行排列组合变换的思路,如下图所示。假设有一个变换,使得输入序列<w1, w2, w3, w4...>经变换后为<x1(w3), x2(w1), x3(w4), x4(w2)...>,某步预测任务为x1,x2,x3 -> x4,即w3, w1, w4 -> w2,便实现了在预测w2时使用了后文w3, w4。
在具体的实现时,并不是对输入真正的进行重排列,而是采用加一层Attention掩码的方法,在Transformer内部进行。这样从输入侧看来没有任何异常。比如,输入<w1, w2, w3, w4>,对于3位置的预测,依赖前1, 2两个位置的词,假设我们有attention掩码<0, 1, 0, 1>,则实现了w2, w4 -> w3预测,如下图右上所示。
双流注意力
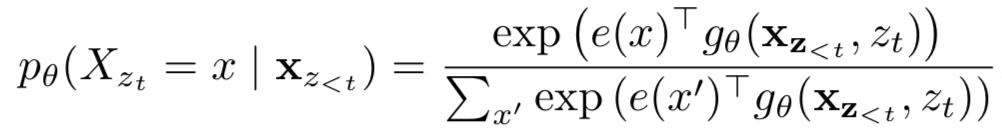
普通的attention弱化了位置信息,BERT通过添加position embedding来修正。XLNet也希望通过类似的方法,如上式所示g。g完成了对两种信息的编码:content embedding和position embedding,二者最终合成word embedding。其先获取position embedding再得出word embedding的迭代往前的思路,无法在一个transformer上实现。由此XLNet设计了双流注意力机制来实现原理上的完备(content+position->word=>next_content+next_position->next_word...)。
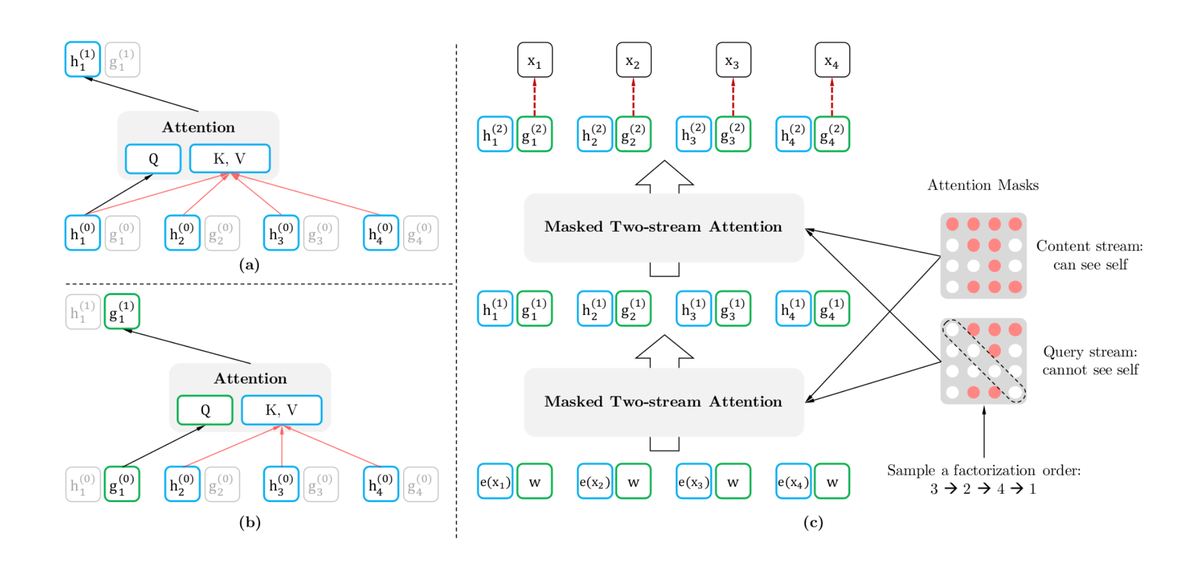
所谓双流分为:content-stream和query-stream,content-stream完成对content embedding的编码,其核心任务是训练hidden_state,query-stream完成对position embedding的编码。如上图所示,content-stream进行包括词自身embedding在内的attention,而query_stream则没有包含词自身的embedding做attention获取权重。
XLNet的双流共享hidden参数,但是输入和隐层embedding却是独立开的,在使用时,直接采用query流即可,其实质上包含了position+content,即我们想要的word_embedding。
6. 小结
本文大致介绍了NLP预训练领域近年的发展,从最初将朴素MLP用户语言模型开始,到word2vec工具的广泛应用,再到后来以BERT为代表的模型级预训练的大放异彩,整个发展史丰富地体现了技术迭代的延续和创新。很多意味还需在以后的工作学习中慢慢体会和发掘。
7. 参考
- A neural probabilistic language model - Bengio.2003
- Distributed Representations of Sentences and Documents - Mikolov.2014
- Efficient estimation of word representations in vector space - Mikolov.2013
- word2vec Parameter Learning Explained - Rong.2014
- Deep contextualized word representations - ME Peters.2018
- Improving Language Understanding by Generative Pre-Training - Radford.2018
- Attention Is All You Need - A Vaswani.2017
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding - J Devlin.2018
- XLNet: Generalized Autoregressive Pretraining for Language Understanding - Z Yang.2019
- 美团BERT的探索和实践
- On word embeddings - Sebastian Ruder.2016
- …